Designed with Deaf experts
The capture protocol follows sign-language components such as hand shapes, movement, orientation, location, and facial expression.
Photorealistic 3D Sign Avatar Modeling and Benchmark
PHOSA introduces MVSign, a multi-view Chinese Sign Language benchmark co-designed with Deaf experts, and a decoupled photorealistic avatar representation for expressive hands and faces.
Abstract
In this work, we focus on photorealistic sign avatar modeling, which is crucial for effective communication with the Deaf community and is characterized by complex hand gestures and nuanced facial expressions. To this end, we introduce MVSign, the first multi-view Chinese sign language dataset co-designed with Deaf experts, featuring diverse gestures and rich annotations. For precise SMPL-X annotation, we develop a hybrid fitting pipeline that produces accurate body, hand, and facial parameters and can also be applied to the monocular setting. Building on MVSign, we propose a decoupled sign avatar representation that isolates body, head, and hand components to capture complex articulations, together with a motion-aware sampling strategy to handle motion blur and balance gesture diversity. Extensive experiments demonstrate that our method achieves high-fidelity visual results on MVSign, particularly in detailed hand and facial regions, and generalizes well to in-the-wild monocular sign language videos. The dataset and code will be publicly released.
MVSign Dataset
The capture protocol follows sign-language components such as hand shapes, movement, orientation, location, and facial expression.
One frontal camera, ten lateral cameras, and five dedicated head views cover body motion, hand articulation, facial expression, and mouthing.
Each sequence includes matting, body-part segmentation, 3D keypoints, and expressive SMPL-X parameters for body, hands, and face.
Hybrid SMPL-X Annotation
PHOSA combines complementary estimators instead of relying on a single whole-body detector. DWPose provides dense 2D keypoints, HaMeR strengthens MANO hand estimates, multi-view triangulation recovers 3D supervision, and INFERNO refines facial expressions. Temporal initialization and SmoothNet reduce high-frequency artifacts across frames.
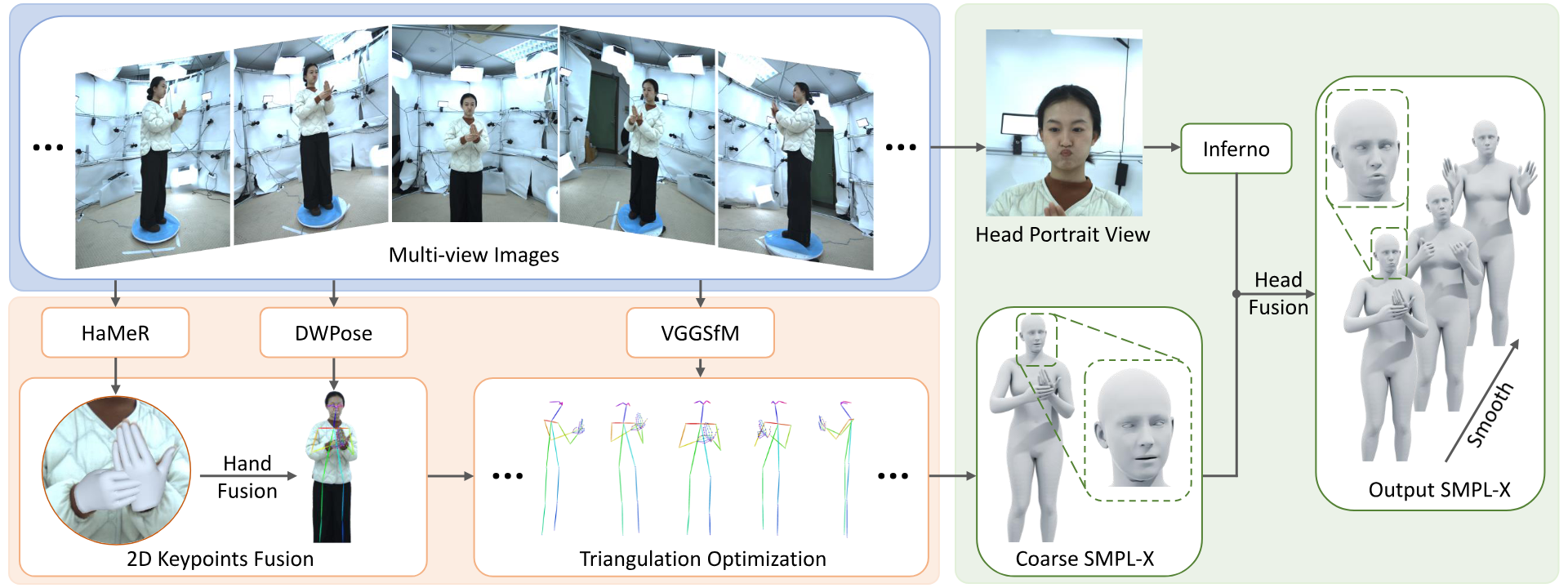
PHOSA Method
Existing avatar models often learn a single whole-body representation, forcing fine hand and facial motion to compete with coarse body movement. PHOSA separates Gaussian maps into body, head, and hands, then applies partial hand kinematic decoupling so hand pose maps depend on hand gestures rather than global body pose.
Benchmark Results
| Method | Full | Hand | Face | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | |
| SplattingAvatar | 23.71 | 0.9625 | 0.0494 | 15.64 | 0.6762 | 0.3884 | 16.90 | 0.7633 | 0.2423 |
| GaussianAvatar | 24.23 | 0.9633 | 0.0428 | 16.30 | 0.6833 | 0.3082 | 17.78 | 0.7737 | 0.2086 |
| AnimatableGS | 25.09 | 0.9647 | 0.0465 | 16.95 | 0.7002 | 0.3135 | 18.63 | 0.7842 | 0.2230 |
| EVA | 25.56 | 0.9667 | 0.0436 | 17.43 | 0.7154 | 0.2869 | 19.21 | 0.8000 | 0.1964 |
| MmlpHuman | 25.91 | 0.9652 | 0.0460 | 17.41 | 0.7084 | 0.2675 | 19.38 | 0.8025 | 0.1869 |
| Ours | 27.03 | 0.9689 | 0.0393 | 18.55 | 0.7325 | 0.2568 | 20.60 | 0.8189 | 0.1757 |
Citation
@inproceedings{wang2026phosa, title = {PHOSA: Photorealistic 3D Sign Avatar Modeling and Benchmark}, author = {Wang, Haodong and Hu, Hezhen and Zhou, Wengang and Li, Houqiang}, booktitle = {European Conference on Computer Vision}, year = {2026}}